Proyek pertama dengan Python
Dalam tutorial langkah demi langkah ini Anda akan:
- Mengnduh dan menginstal Python SciPy
- Memuat dataset dan memaahami strukturnya menggunakan summary statistik dan visualisasi data.
- Menggunakan 6 model algoritma pembelajaran mesin, pilih yang terbaik, dan membangun keyakinan agar akurasinya dapat diandalkan.
Pemula Membutuhkan Proyek Kecil End-to-End
Langkah mengerjakan proyek dalam Machine learning:
- Definisikan Masalah.
- Siapkan Data.
- Evaluasi Algoritma.
- Tingkatkan akurasi Hasil.
- Menyajikan hasil
Cara terbaik untuk benar-benar memahami adalah dengan mengerjakan proyek pembelajaran mesin secara menyeluruh dan mencakup kelima langkah-langkah utama di atas. Yaitu mulai dari memuat data, melakukan summary data, mengevaluasi algoritma dan membuat beberapa prediksi.
Jika Anda pernah melakukan kelima langkahnya, Anda memiliki template yang dapat Anda gunakan pada dataset lainnya.
Hello World - Pembelajaran Mesin
Proyek kecil terbaik untuk memulai dengan pembelajaran mesin adalah klasifikasi bunga iris (yaitu dataset iris ).
Data ini adalah proyek yang bagus karena sangat mudah dipahami.
- Atribut bersifat numerik sehingga harus merepresentasikan cara untuk memuat dan menangani data.
- Bisa dipakai untuk masalah klasifikasi, yang memungkinkan untuk berlatih dengan jenis algoritma supervised machine learning yang mungkin lebih mudah.
- Data ini mempunyai masalah klasifikasi multi-kelas (multi-nominal) yang mungkin memerlukan beberapa penanganan khusus.
- Data ini hanya memiliki 4 atribut dan 150 baris, artinya data kecil dan mudah masuk ke dalam memori.
- Semua atribut numerik berada dalam unit yang sama dan skala yang sama, tidak memerlukan penskalaan atau transformasi khusus untuk memulai.
Pembelajaran Mesin dengan Python: Tutorial Langkah-demi-Langkah
Di bagian ini, kita akan mengerjakan proyek pembelajaran mesin skala kecil secara menyeluruh.
Berikut adalah ikhtisar dari apa yang akan kita bahas:
- Menginstal platform Python dan SciPy.
- Memuat dataset.
- Melakukan summary dataset.
- Memvisualisasikan dataset.
- Mengevaluasi beberapa algoritma.
- Membuat beberapa prediksi.
1. Mengunduh, Menginstal, dan Memulai Python SciPy
1.1 Instal Perpustakaan SciPy
Tutorial ini mengasumsikan versi Python 2.7 atau 3.6+.
Ada 5 perpustakaan utama yang perlu Anda instal. Di bawah ini adalah daftar pustaka Python SciPy yang diperlukan untuk tutorial ini:
- scipy
- numpy
- matplotlib
- panda
- sklearn
Ada banyak cara untuk menginstal perpustakaan ini. Saran terbaik adalah memilih satu metode kemudian konsisten dalam menginstal setiap library.
Halaman instalasi scipy memberikan instruksi yang sangat baik untuk menginstal library di atas pada berbagai platform yang berbeda, seperti Linux, mac OS X dan Windows.
Catatan : Tutorial ini mengasumsikan Anda telah menginstal scikit-learn versi 0.20 atau lebih tinggi.
1.2 Memulai dan memeriksa versi Python
Sebaiknya pastikan lingkungan Python Anda berhasil diinstal dan berfungsi seperti yang diharapkan.
Skrip di bawah ini akan membantu Anda menguji lingkungan Anda denganmengimpor setiap perpustakaan yang diperlukan dalam tutorial ini dan mencetak versinya.
Buka baris perintah dan mulai python:
Ketik atau salin dan tempel skrip berikut:
Output:
Bandingkan output di atas dengan versi Anda.
Idealnya, versi Anda harus cocok atau lebih baru. API tidak berubah dengan cepat, jadi jangan terlalu khawatir jika Anda ketinggalan beberapa versi, Semua yang ada di tutorial ini kemungkinan besar akan tetap berfungsi untuk Anda.
Jika Anda tidak dapat menjalankan skrip di atas dengan bersih, Anda tidak akan dapat menyelesaikan tutorial ini. Jika ada masalah bisa tanya di link ini: Stack Exchange.
2. Memuat Data
Kita akan menggunakan dataset bunga iris. Dataset ini terkenal karena digunakan sebagai dataset "hello world" dalam pembelajaran mesin dan statistik oleh hampir semua orang.
Dataset ini berisi 150 pengamatan bunga iris. Ada empat kolom pengukuran bunga dalam sentimeter. Kolom kelima adalah jenis bunga yang diamati. Semua bunga yang diamati milik salah satu dari tiga spesies.
Anda dapat mempelajari lebih lanjut tentang kumpulan data ini di Wikipedia .
Pada langkah ini kita akan memuat data iris dari URL file CSV.
2.1 Mengimpor Library
Pertama, mari impor semua modul, fungsi, dan objek yang akan kita gunakan dalam tutorial ini
Semuanya harus dimuat tanpa kesalahan. Jika Anda memiliki kesalahan, berhenti dan pastikan Anda memiliki lingkungan SciPy yang berfungsi sebelum melanjutkan. Lihat saran di atas tentang menyiapkan lingkungan Anda.
2.2 Memuat Dataset
Kita dapat memuat data langsung dari repositori Pembelajaran Mesin UCI.
Kita menggunakan panda untuk memuat data. Kita juga akan menggunakan panda selanjutnya untuk mengeksplorasi data baik dengan statistik deskriptif maupun visualisasi data.
Perhatikan bahwa kita menentukan nama setiap kolom saat memuat data. Ini akan membantu nanti ketika kita mengeksplorasi data.
Dataset harus berhasil dimuat tanpa insiden.
Jika Anda memiliki masalah jaringan, Anda dapat mengunduh file iris.csv ke direktori kerja Anda dan memuatnya menggunakan metode yang sama, mengubah URL ke nama file lokal.
3. Summari Dataset
Sekarang saatnya untuk melihat data.
Pada langkah ini kita akan melihat data dengan beberapa cara berbeda:
- Dimensi kumpulan data.
- Mengintip data itu sendiri.
- Ringkasan statistik dari semua atribut.
- Perincian data menurut variabel kelas.
Jangan khawatir, setiap melihat data adalah satu perintah. Ini adalah perintah berguna yang dapat Anda gunakan lagi dan lagi di proyek mendatang.
3.1 Dimensi Dataset
Kita bisa mendapatkan gambaran singkat tentang berapa banyak instance (baris) dan berapa banyak atribut (kolom) yang dikandung data dengan properti shape.
Anda akan melihat 150 instance dan 5 atribut:
3.2 Melihat Data
Ini merupakan ide yang baik untuk benar-benar memperhatikan data Anda.
Anda akan melihat 20 baris pertama data:
3.3 Summary Statistik
Sekarang kita dapat melihat ringkasan dari setiap atribut.
Ini termasuk jumlah, rata-rata, nilai min dan max serta beberapa persentil.
Kita dapat melihat bahwa semua nilai numerik memiliki skala yang sama (sentimeter) dan rentang yang sama antara 0 dan 8 sentimeter.
3.4 Distribusi Kelas
Sekarang mari kita lihat jumlah instance (baris) yang dimiliki setiap kelas. Kita dapat melihat ini sebagai hitungan mutlak.
Sekarang mari kita lihat jumlah instance (baris) yang dimiliki setiap kelas. Kita dapat melihat ini sebagai hitungan mutlak.
Kita dapat melihat bahwa setiap kelas memiliki jumlah instance yang sama (50 atau 33% dari dataset).
3.5 Contoh Lengkap
Sebagai referensi, kita dapat mengikat semua elemen sebelumnya menjadi satu skrip.
Contoh lengkapnya tercantum di bawah ini.
4. Visualisasi Data
Kami sekarang memiliki ide dasar tentang data. Kita perlu memperluasnya dengan beberapa visualisasi.
Kita akan melihat dua jenis plot:
- Plot univariat untuk lebih memahami setiap atribut.
- Plot multivariasi untuk lebih memahami hubungan antar atribut.
4.1 Plot Univariat
Kita mulai dengan beberapa plot univariat, yaitu plot dari setiap variabel individu.
Mengingat bahwa variabel input adalah numerik, kita dapat membuat plot kotak dan kumis masing-masing.
Ini memberi kita gagasan yang lebih detil tentang distribusi dari atribut input:
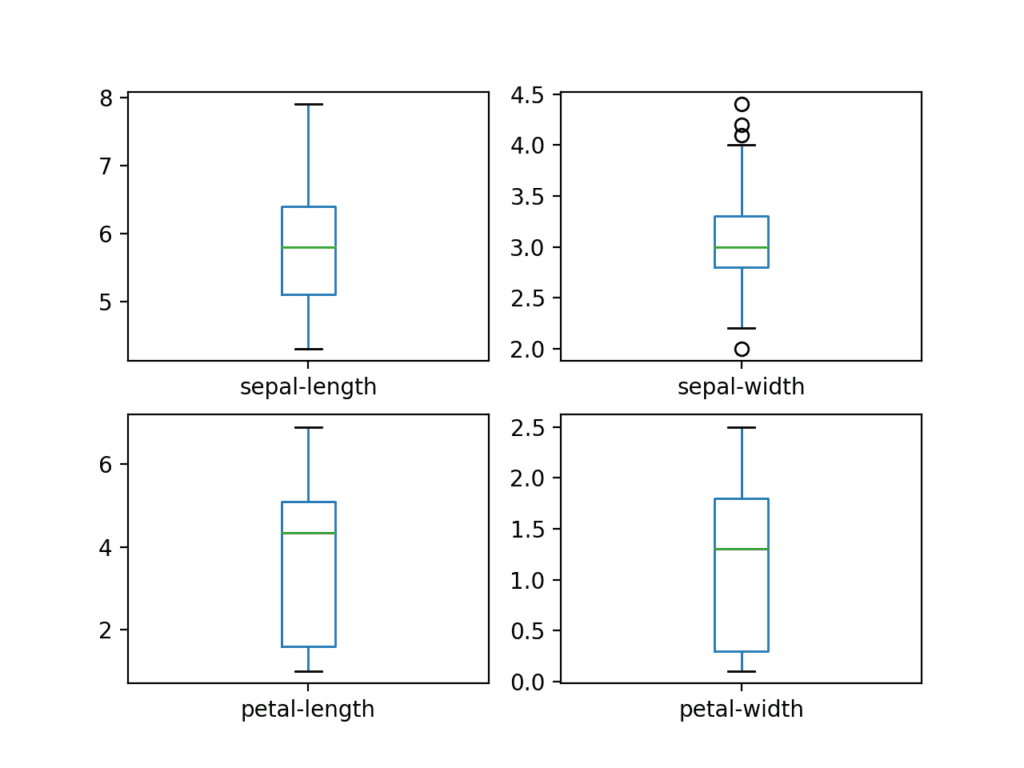
Box and Whisker Plots for Each Input Variable for the Iris Flowers Dataset
We can also create a histogram of each input variable to get an idea of the distribution.
It looks like perhaps two of the input variables have a Gaussian distribution. This is useful to note as we can use algorithms that can exploit this assumption.
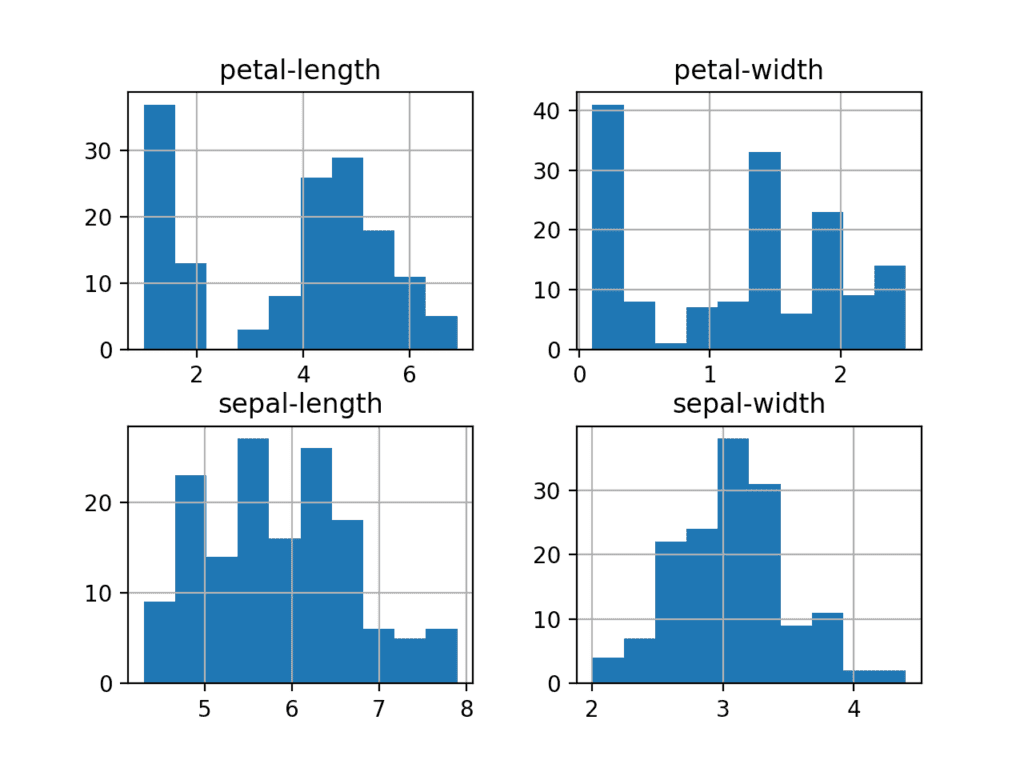
Histogram Plots for Each Input Variable for the Iris Flowers Dataset
4.2 Plot Multivariat
Sekarang kita dapat melihat interaksi antar variabel.
Pertama, mari kita lihat scatterplot dari semua pasangan atribut. Ini dapat membantu untuk melihat hubungan terstruktur antara variabel input.
Perhatikan pengelompokan diagonal dari beberapa pasang atribut. Ini menunjukkan korelasi yang tinggi dan hubungan yang dapat diprediksi.
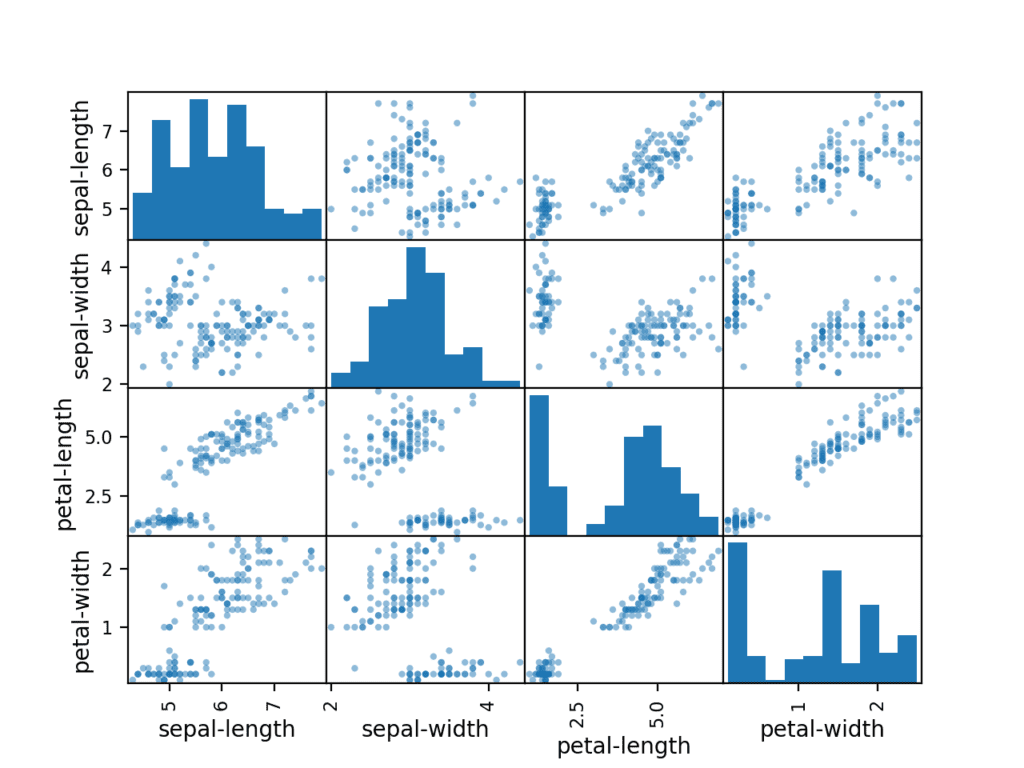
Scatter Matrix Plot untuk Setiap Variabel Input untuk Dataset Bunga Iris
4.2 Contoh Lengkap
Sebagai referensi, kita dapat menggabung semua elemen sebelumnya menjadi satu skrip.
Contoh lengkapnya tercantum di bawah ini.
5. Evaluasi Beberapa Algoritma
Sekarang saatnya untuk membuat beberapa model data dan memperkirakan keakuratannya pada data yang tidak terlihat.
Inilah yang akan kita bahas dalam langkah ini:
- Pisahkan set data validasi.
- Siapkan test harness untuk menggunakan validasi silang 10 kali lipat.
- Bangun beberapa model berbeda untuk memprediksi spesies dari pengukuran bunga
- Pilih model terbaik.
5.1 Membuat Dataset Validasi
Perlu kita ketahui bahwa model yang kita buat sudah bagus.
Nantinya, kita akan menggunakan metode statistik untuk memperkirakan keakuratan model yang kita buat pada data yang tidak terlihat. Kita juga menginginkan perkiraan yang lebih konkret dari akurasi model terbaik pada data yang tidak terlihat dengan mengevaluasinya pada data yang tidak terlihat sebenarnya.
Artinya, kita akan membagi beberapa data yang tidak dapat dilihat oleh algoritma dan menggunakan data ini untuk mendapatkan ide kedua dan independen tentang seberapa akurat model terbaik sebenarnya.
Kita akan membagi kumpulan data yang dimuat menjadi dua, 80% di antaranya akan kita gunakan untuk melatih, mengevaluasi, dan memilih di antara model kami, dan 20% yang akan kita simpan sebagai kumpulan data validasi.
You now have training data in the X_train and Y_train for preparing models and a X_validation and Y_validation sets that we can use later.
Notice that we used a python slice to select the columns in the NumPy array. If this is new to you, you might want to check-out this post:
5.2 Test Harness
We will use stratified 10-fold cross validation to estimate model accuracy.
This will split our dataset into 10 parts, train on 9 and test on 1 and repeat for all combinations of train-test splits.
Stratified means that each fold or split of the dataset will aim to have the same distribution of example by class as exist in the whole training dataset.
For more on the k-fold cross-validation technique, see the tutorial:
We set the random seed via the random_state argument to a fixed number to ensure that each algorithm is evaluated on the same splits of the training dataset.
The specific random seed does not matter, learn more about pseudorandom number generators here:
We are using the metric of ‘accuracy‘ to evaluate models.
This is a ratio of the number of correctly predicted instances divided by the total number of instances in the dataset multiplied by 100 to give a percentage (e.g. 95% accurate). We will be using the scoring variable when we run build and evaluate each model next.
5.3 Build Models
We don’t know which algorithms would be good on this problem or what configurations to use.
We get an idea from the plots that some of the classes are partially linearly separable in some dimensions, so we are expecting generally good results.
Let’s test 6 different algorithms:
- Logistic Regression (LR)
- Linear Discriminant Analysis (LDA)
- K-Nearest Neighbors (KNN).
- Classification and Regression Trees (CART).
- Gaussian Naive Bayes (NB).
- Support Vector Machines (SVM).
This is a good mixture of simple linear (LR and LDA), nonlinear (KNN, CART, NB and SVM) algorithms.
Let’s build and evaluate our models:
5.4 Select Best Model
We now have 6 models and accuracy estimations for each. We need to compare the models to each other and select the most accurate.
Running the example above, we get the following raw results:
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
What scores did you get?
Post your results in the comments below.
In this case, we can see that it looks like Support Vector Machines (SVM) has the largest estimated accuracy score at about 0.98 or 98%.
We can also create a plot of the model evaluation results and compare the spread and the mean accuracy of each model. There is a population of accuracy measures for each algorithm because each algorithm was evaluated 10 times (via 10 fold-cross validation).
A useful way to compare the samples of results for each algorithm is to create a box and whisker plot for each distribution and compare the distributions.
We can see that the box and whisker plots are squashed at the top of the range, with many evaluations achieving 100% accuracy, and some pushing down into the high 80% accuracies.
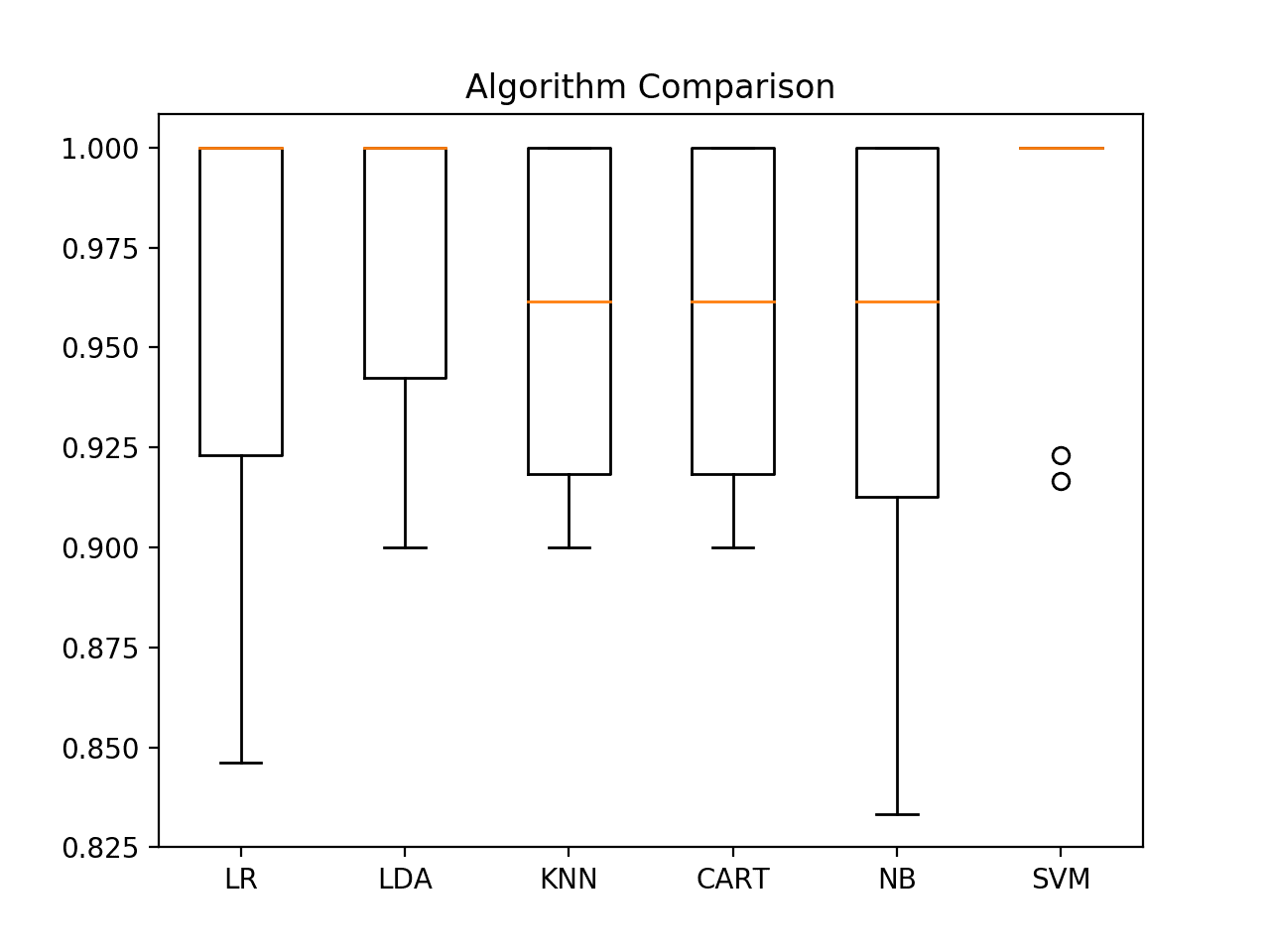
Box and Whisker Plot Comparing Machine Learning Algorithms on the Iris Flowers Dataset
5.5 Complete Example
For reference, we can tie all of the previous elements together into a single script.
The complete example is listed below.
6. Make Predictions
We must choose an algorithm to use to make predictions.
The results in the previous section suggest that the SVM was perhaps the most accurate model. We will use this model as our final model.
Now we want to get an idea of the accuracy of the model on our validation set.
This will give us an independent final check on the accuracy of the best model. It is valuable to keep a validation set just in case you made a slip during training, such as overfitting to the training set or a data leak. Both of these issues will result in an overly optimistic result.
6.1 Make Predictions
We can fit the model on the entire training dataset and make predictions on the validation dataset.
You might also like to make predictions for single rows of data. For examples on how to do that, see the tutorial:
You might also like to save the model to file and load it later to make predictions on new data. For examples on how to do this, see the tutorial:
6.2 Evaluate Predictions
We can evaluate the predictions by comparing them to the expected results in the validation set, then calculate classification accuracy, as well as a confusion matrix and a classification report.
We can see that the accuracy is 0.966 or about 96% on the hold out dataset.
The confusion matrix provides an indication of the errors made.
Finally, the classification report provides a breakdown of each class by precision, recall, f1-score and support showing excellent results (granted the validation dataset was small).
6.3 Complete Example
For reference, we can tie all of the previous elements together into a single script.
The complete example is listed below.
You Can Do Machine Learning in Python
Work through the tutorial above. It will take you 5-to-10 minutes, max!
You do not need to understand everything. (at least not right now) Your goal is to run through the tutorial end-to-end and get a result. You do not need to understand everything on the first pass. List down your questions as you go. Make heavy use of the help (“FunctionName”) help syntax in Python to learn about all of the functions that you’re using.
You do not need to know how the algorithms work. It is important to know about the limitations and how to configure machine learning algorithms. But learning about algorithms can come later. You need to build up this algorithm knowledge slowly over a long period of time. Today, start off by getting comfortable with the platform.
You do not need to be a Python programmer. The syntax of the Python language can be intuitive if you are new to it. Just like other languages, focus on function calls (e.g. function()) and assignments (e.g. a = “b”). This will get you most of the way. You are a developer, you know how to pick up the basics of a language real fast. Just get started and dive into the details later.
You do not need to be a machine learning expert. You can learn about the benefits and limitations of various algorithms later, and there are plenty of posts that you can read later to brush up on the steps of a machine learning project and the importance of evaluating accuracy using cross validation.
What about other steps in a machine learning project. We did not cover all of the steps in a machine learning project because this is your first project and we need to focus on the key steps. Namely, loading data, looking at the data, evaluating some algorithms and making some predictions. In later tutorials we can look at other data preparation and result


Comments
Post a Comment